
Authors: 
In this blog post, we discuss Edico Genome’s DRAGEN Bio-IT Platform for rapid secondary analysis. We benchmark DRAGEN for speed and accuracy on diverse WGS datasets. Finally, we detail how Edico Genome and DNAnexus collaborated to improve the DRAGEN pipeline performance on noisy datasets and PCR-samples in the newest version.
Introduction – DRAGEN and FPGAs
 Sequencing volume continues to grow exponentially, exceeding the increase in CPU speed. As this growth strains analytical capacity, it creates demand for fast and efficient analysis approaches (and platforms like DNAnexus to coordinate them). Edico Genome develops genomic pipelines that leverage specialized Field Programmable Gate Array (FPGAs) to dramatically increase analysis speed.
Sequencing volume continues to grow exponentially, exceeding the increase in CPU speed. As this growth strains analytical capacity, it creates demand for fast and efficient analysis approaches (and platforms like DNAnexus to coordinate them). Edico Genome develops genomic pipelines that leverage specialized Field Programmable Gate Array (FPGAs) to dramatically increase analysis speed.
Each move along the spectrum of CPU -> GPU -> FPGA -> ASIC hardware trades programming/execution flexibility for speed and efficiency. With skill, FPGAs are reprogrammable, allowing Edico Genome to load its algorithms into compatible cloud hardware and to update this logic. DRAGEN is available on DNAnexus as a platform app.
Edico Genome’s speed has proven critical in time-sensitive applications, such as rapid diagnosis of newborns in the NICU at Rady Children’s Hospital – a mutual Edico Genome-DNAnexus customer.
Notes on Proper Training and Evaluation of Your DRAGEN
DNAnexus recently released a method to generate real, noisy NGS data called Readshift (blog) – (code). Edico Genome has produced a new version of their WGS tools, labeled DRAGEN V2+, which we evaluate on Readshift.
First, we present evaluations on an HG002 benchmark dataset which was never made available to Edico Genome to ensure that the improvements apply generally. This set of benchmarks use 35X PCR-free WGS data with the hs37d5 reference. Evaluation is performed using the same methods as used on precisionFDA. We compare DRAGEN V2 (the prior version) to DRAGEN V2+ to demonstrate Edico Genome’s rapid improvement.
DRAGEN-Scale: How Fast is DRAGEN?
Figure 1 compares execution speed of DRAGEN relative to popular pipelines executed on DNAnexus. For many of these apps (e.g. GATK3), DNAnexus has applied additional optimizations to improve parallelism, meaning they are faster than they would be on local infrastructure. When time is critical, DRAGEN V2 and V2+ are the clear leader.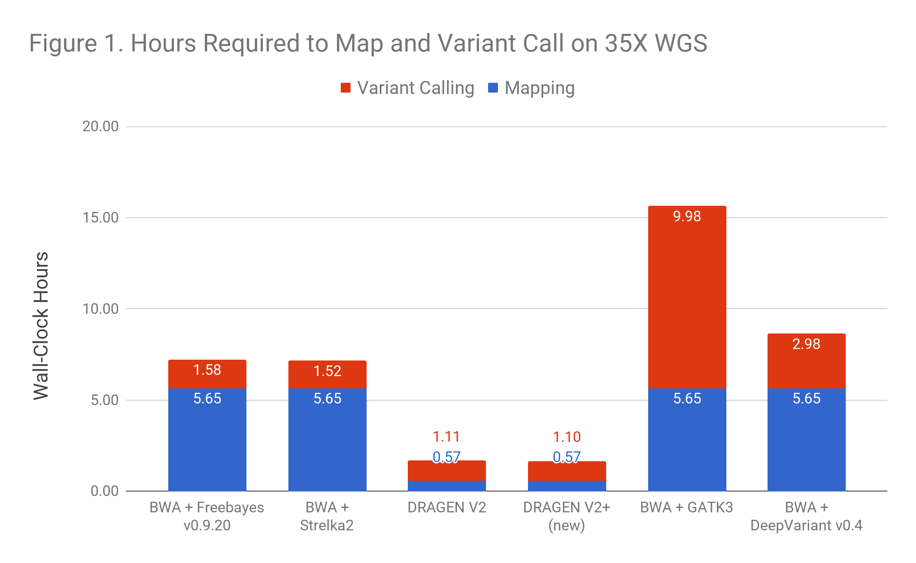
DRAGEN accelerates both the mapping process and variant calling, which can be run independently. This allows users to mix-and-match if a specific variant caller is required. Upstream of the secondary analysis, Edico Genome makes an accelerated BCL2FASTQ tool which greatly improves speed and efficiency while producing identical FASTQs.
How Accurate is DRAGEN?
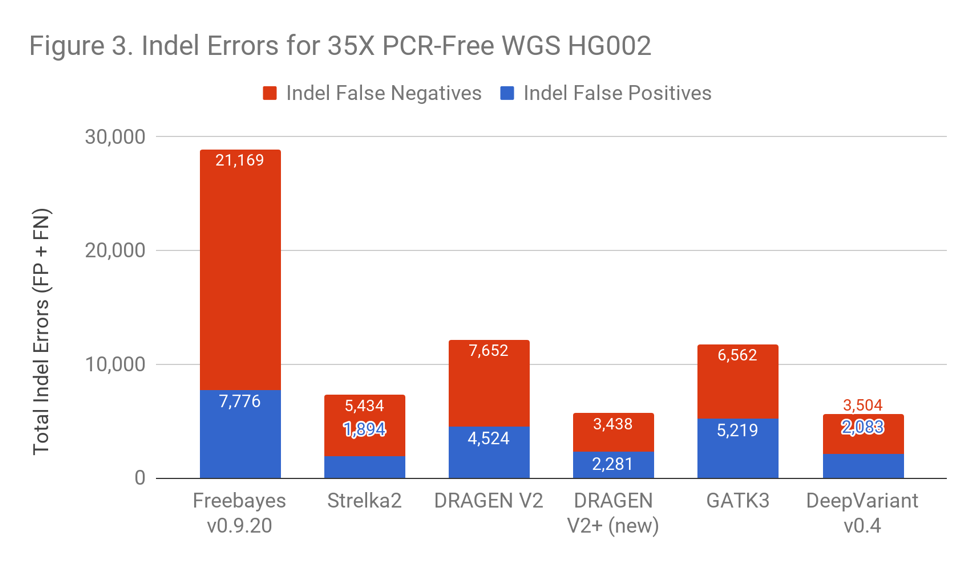
Figures 2 and 3 demonstrate that DRAGEN’s speed does not come at the expense of accuracy. The newest version of DRAGEN achieves a ~40% reduction in SNP Error rate and ~50% reduction in Indel Error rate. Edico Genome was also recently designated as one of the winners of the precisionFDA Hidden Treasures Challenge.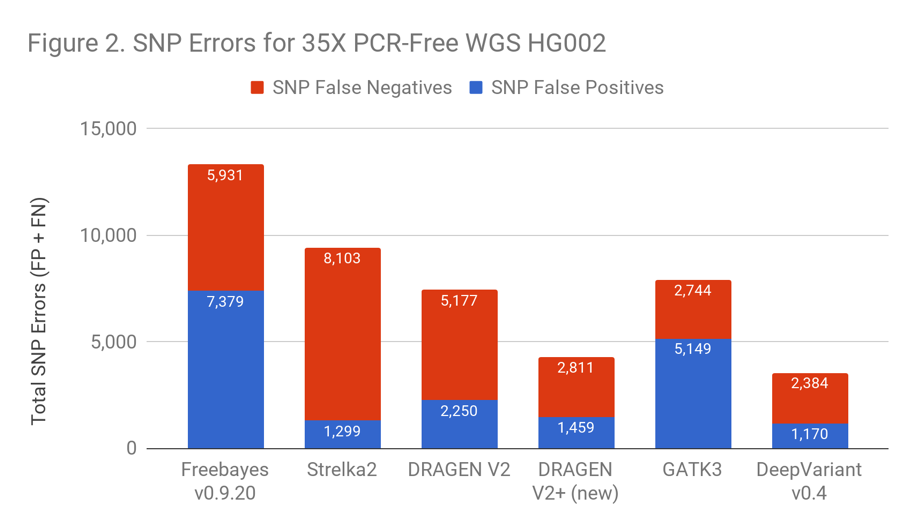
How to Train Your DRAGEN – New Improvements in DRAGEN V2+
The recent DNAnexus Readshift blog post compared pipeline performance in a number of noisy conditions. After this blog, DNAnexus and Edico Genome discussed improvements based on the findings of Readshift. Edico Genome rapidly iterated several new development versions which we built as DNAnexus Platform apps, evaluated, and discussed with Edico Genome.
These benchmarks are conducted with the same methods as on precisionFDA. Here we use the hg38 reference. For DRAGEN and GATK4 we use hg38 with ALT contigs. For other callers, we use the hg38 reference with decoy sequences, but without ALT contigs.
The labels +0.0 std, +0.5 std, etc… indicate a sample with X standard deviations worse average base quality than baseline. Think of these as progressively harder. (Full details)
Greater Accuracy on PCR Samples
In both the Readshift blog and an earlier DeepVariant blog, we noticed that certain HiSeqX samples caused much worse indel calling performance. We subsequently realized that these samples were the only non PCR-free ones. The use of PCR in samples is required in several cases, e.g. small DNA inputs, as well as new fast and automated-prep Illumina Nextera Flex kits. Strelka2’s strong results suggest that Illumina took special care to consider performance in PCR samples, and that other callers could learn similarly.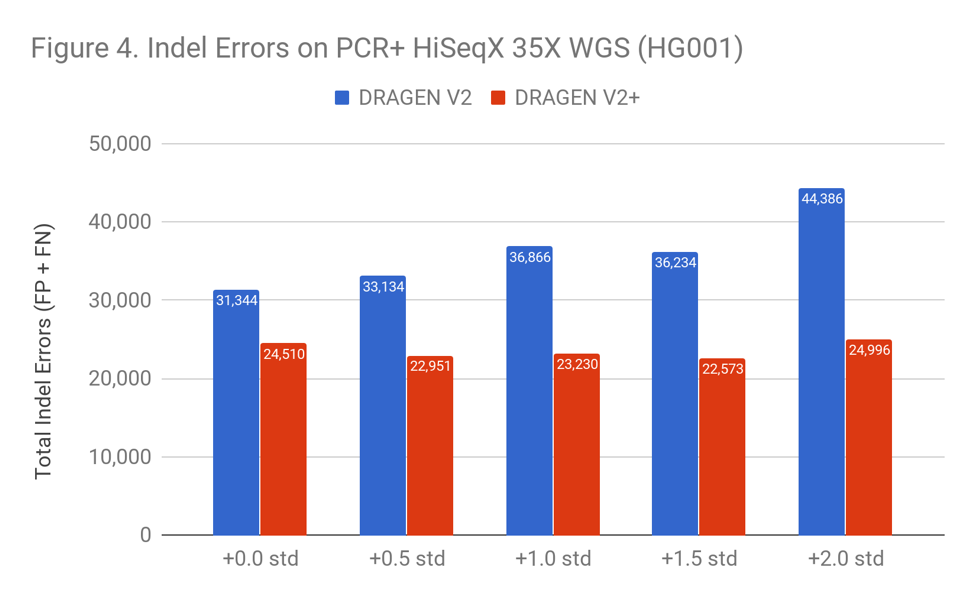 DRAGEN’s performance now matches Strelka2’s on these samples as leading the pack in performance for indels on PCR samples (the error mode that dominates in these samples).
DRAGEN’s performance now matches Strelka2’s on these samples as leading the pack in performance for indels on PCR samples (the error mode that dominates in these samples).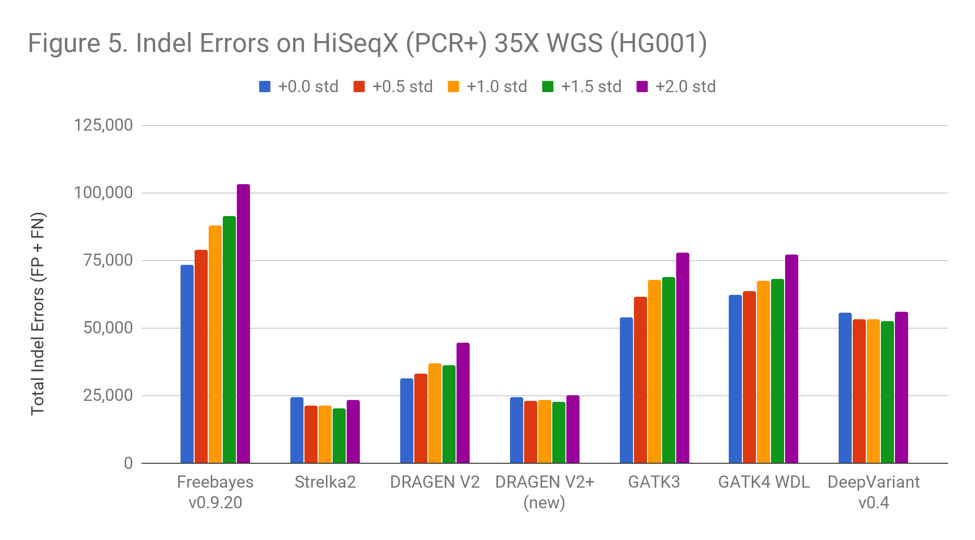 Improved Robustness Against Low-Quality Reads
Improved Robustness Against Low-Quality Reads
Readshift’s main focus was to understand how calling performance degrades as the quality of a sequence run decreases. DRAGEN V2+ is not only more accurate, it is also able to resist the effect of lower quality reads up to the most extreme shift of +2.0 std.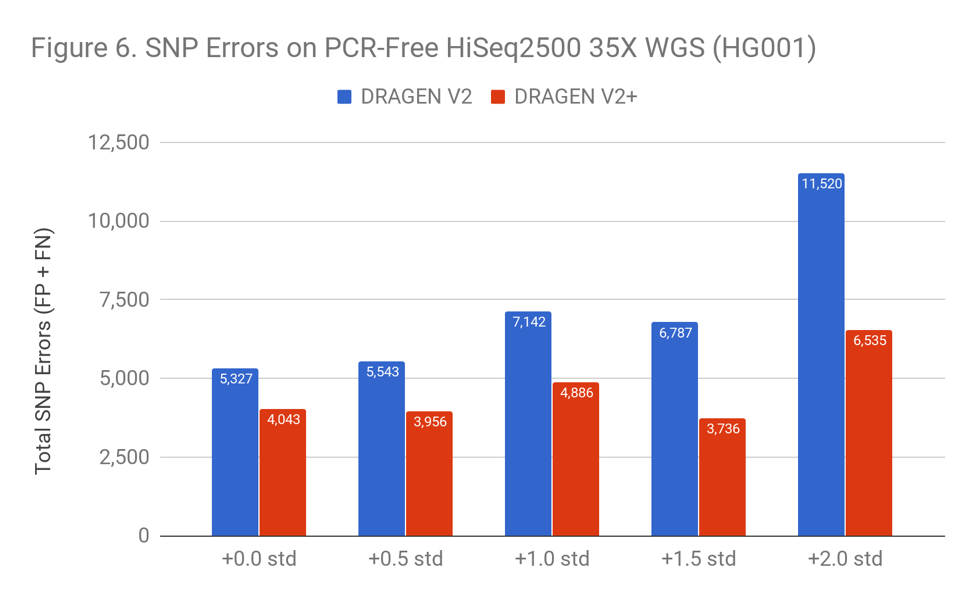
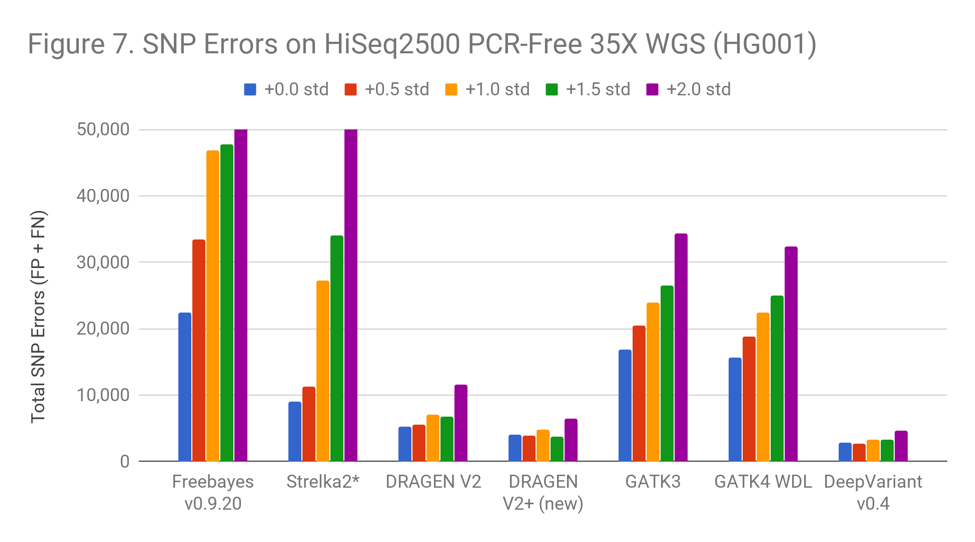
* Discussion with Chris Saunders of Illumina indicates that a specific heuristic for SNP calling in Strelka2 may be interacting with Readshift. We are working to make a version of Readshift which will not trigger this heuristic for a more accurate Strelka2 evaluation.
Faster Runtime on NovaSeq Samples
Readshift identified that low-quality NovaSeq data can lead to dramatically longer runtime (or program crashes). Brad Chapman has completed an excellent investigation into the use of read trimming in somatic calling that may help this and more broadly.
Edico Genome has made improvements to the runtime of DRAGEN on NovaSeq samples across the board, demonstrating the ability to quickly improve for new data types.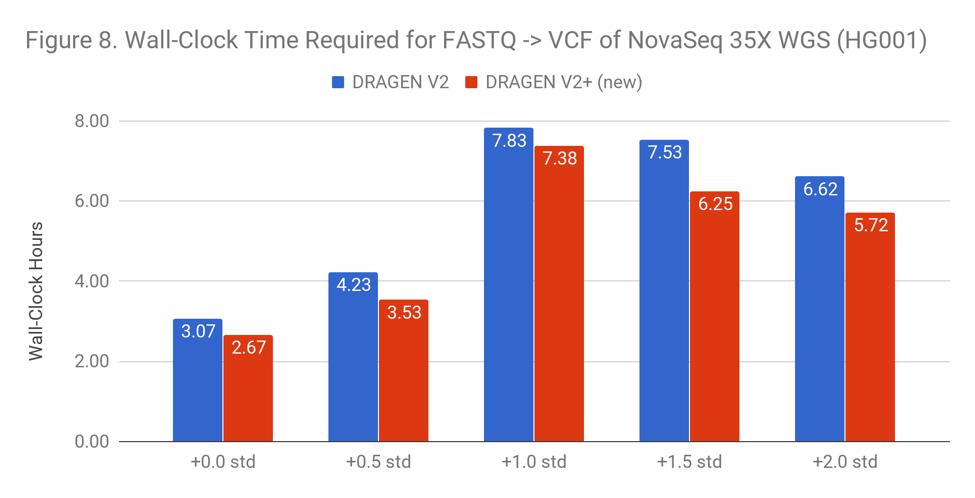
However, the relative slowdown in low-quality NovaSeq samples remains. DNAnexus and Edico are continuing discussions on how to improve this issue.
Future Directions
In addition, Edico Genome recently released its new DRAGEN Virtual Long Read Detection (VLRD) Pipeline (Coming Soon to DNAnexus), designed at achieving greater accuracy in segmental duplications than standard variant callers. In this pipeline, Edico Genome leverages the fact that because DRAGEN computes so quickly, they can leverage computationally intensive assembly-based techniques and jointly calling all regions that are similar. We hope to take a deeper investigation into this method (and these difficult, but important, regions of the genome) in a future blog. Based on the responsiveness of Edico in these collaborations, we are quite convinced there will be a:
How to Train your DRAGEN 2
Edico’s Genome’s DRAGEN is available now as an easy to use app on DNAnexus. To pilot using DRAGEN V2+ on DNAnexus in your workflow, email edico@dnanexus.com.


.png)
.png)
.png)
{kind=link}