

Yesterday, the Google Brain team released DeepVariant – an updated, open-source (github) deep learning based variant caller. A previous version of DeepVariant was first submitted to the DNAnexus-powered PrecisionFDA platform, winning the award for overall accuracy in SNP calling in the PrecisionFDA Truth Challenge. A manuscript describing DeepVariant has been on bioRxiv, giving the field an understanding of the application, but full peer-reviewed publication has presumably been waiting for this open-sourced version.
We’re excited by this new method and are making it available to our customers on the DNAnexus Platform. We’ve done an evaluation of DeepVariant to assess its performance relative to other variant calling solutions. In this post, we will present that evaluation as well as a brief discussion of deep learning and the mechanics of DeepVariant.
We are pleased to announce the launch of the DeepVariant Pilot Program, to be offered to a limited number of interested users, with broader access to the tool in the coming months. Access DeepVariant now on the DNAnexus platform.
What is Deep Learning?
Recent advancements in computing power and data scale have allowed multi-layer, complex architecture – or “deep” Neural Networks to demonstrate that their “learning plateau” is significantly higher than other statistical methods that previously supplanted them.
Generally, deep learning networks are fed relatively raw data. Early layers in the network learn “coarse” features on their own (for example, edge detection in vision). Later layers contain abstract/higher-level information. The ability of these deep networks to perform well is highly dependent on the architecture of the neural network – only certain configurations allow information to combine in ways that build meaning.
Google, has pushed the leading edge of deep learning, with its open-source framework, TensorFlow, and with powerful demonstrations ranging from machine translation to world champion level Go to optimizing energy use in data centers.
What is DeepVariant?
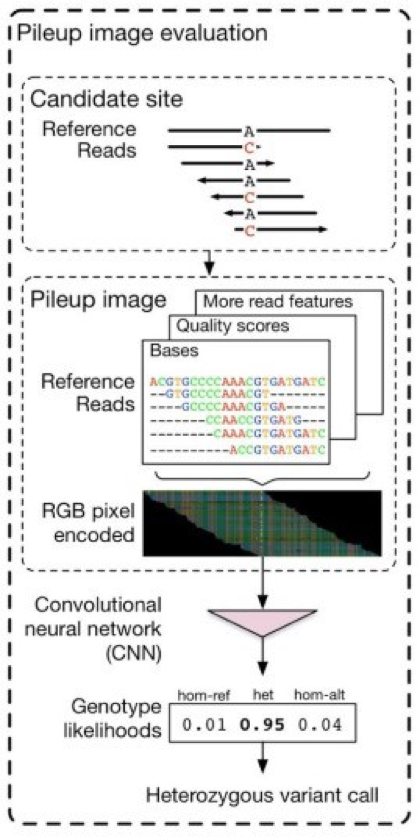 DeepVariant applies the Inception TensorFlow framework, which was originally developed to perform image classification. DeepVariant converts a BAM into images similar to genome browser snapshots and then classifies the positions as variant or non-variant. Conceptually, it uses the idea that if a person can leverage a genome browser to determine if a call is real, a sufficiently smart framework should be able to make the same determination.
DeepVariant applies the Inception TensorFlow framework, which was originally developed to perform image classification. DeepVariant converts a BAM into images similar to genome browser snapshots and then classifies the positions as variant or non-variant. Conceptually, it uses the idea that if a person can leverage a genome browser to determine if a call is real, a sufficiently smart framework should be able to make the same determination.
The first part is to make examples that represent candidate sites. This involves finding all of the positions that have even a small chance of being variants with a very sensitive caller. In addition, DeepVariant performs a type of local reassembly which serves as a more thorough version of indel realignment. Finally, multi-dimensional pileup images are produced for the image classifier.
The second part is to call variants using the TensorFlow framework. This passes the images through the Inception architecture that has been trained to recognize the signatures of SNP and Indel variant positions.
Both components are computationally intensive. Because care was taken to plug into the TensorFlow framework for GPU acceleration, the call variants step can be accomplished much faster if a GPU machine is available. When Google’s specially designed TPU hardware becomes available, this step may become dramatically faster and cheaper.
The make examples component uses several more traditional approaches, which are more difficult to accelerate, and also computationally intensive. As efficiency gains from GPU or TPU improve call variants, the make examples step may limit the ultimate speed and cost. However, given the attractiveness of a fully deep learning approach, the genomics team at Google Brain would not have included these steps lightly. The genomics team at Google Brain includes some of the pioneers (Mark DePristo and Ryan Poplin) of Indel Realignment and Haplotype construction from the development of GATK.
The Inception framework is a “heavy-weight” deep learning architecture, meaning it is computationally expensive to train and to apply. It should not be assumed that all problems in genomics will require the application of Inception. Currently in the field of deep learning, building customized architecture to solve a problem is challenging and time consuming – so the application of a proven architecture makes sense. In the long term, custom-built architectures for genomics may become more prevalent.
Although the PrecisionFDA version of DeepVariant represents the first application of deep learning to SNP and Indel calling, the Campagne lab has recently uploaded a manuscript on bioRxiv detailing a framework to train SNP and Indel models. Jason Chin has also written an excellent tutorial with a demonstration framework.
How Accurate is DeepVariant?
To understand how DeepVariant performs on real samples, we compared it against several other methods in diverse WGS settings. To quickly summarize, its accuracy represents a significant improvement over current state of the art across a diverse set of tests.
Assessments on our standard benchmark sets
At DNAnexus, we have a standard benchmarking set on HG001, HG002, and HG005. These are built from the Genome in a Bottle Truth Sets. We use this internally to assess methods and to make the best recommendations on tool selection and use for our customers. In each case, we assess on the confident regions for the respective genomes. The assessment is done via the same app as on PrecisionFDA, using hap.py from Illumina. In all cases, except where explicitly mentioned, the reads used represent 35X coverage WGS samples achieved through random downsampling.
The following charts show the number of SNP and Indel errors on several samples (lower numbers are better in these graphs). *Samtools not shown in Indel plots due to high indel error rate
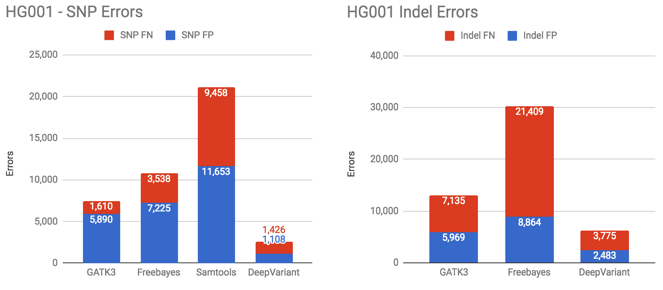
DeepVariant dramatically outperforms other methods in SNPs on this sample, with almost a 10-fold error reduction. SNP F-measure is 0.9996. For indels, DeepVariant is also the clear winner.
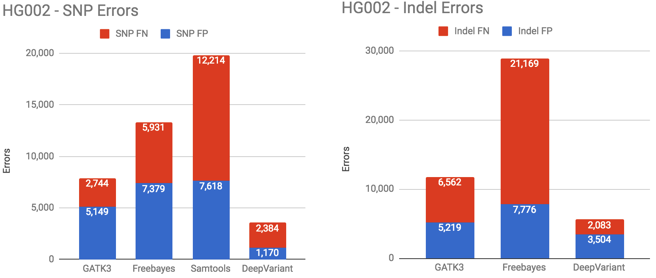
When DeepVariant is applied to a different human genome – the Ashkenazim HG002 set from Genome in a Bottle – its performance is similarly strong.
Assessments on Diverse Benchmark Sets
Following our standard benchmarks, we sought to determine whether we could identify samples where DeepVariant would perform poorly. With machine-learning models, there is some concern that they may over-fit to their training conditions.
Early Garvan HiSeqX runs – In 2014, the Garvan Institute made the first public release of a HiSeqX Genome available through DNAnexus. As occurs with new sequencers, the first runs from HiSeqX machines were generally of lower quality compared to runs produced after years of improvements to experience, reagents, and process. In 2016, Garvan produced a PCR-free HiSeqX run as a high-quality data set for the PrecisionFDA Consistency Challenge.
To better assess the performance of DeepVariant on samples of varying polish, we applied it and other open-source methods to each of these genomes.
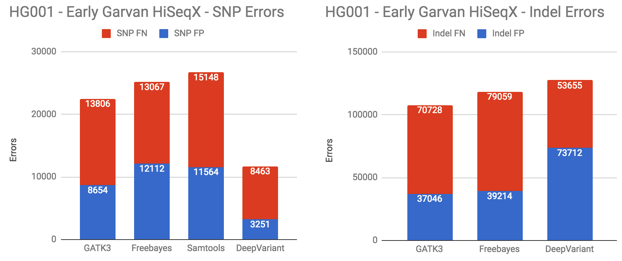
In the 2014 Garvan HiSeqX run, DeepVariant retains a significant advantage in SNP calling. However, it performs worse in indel calling. Note that all callers had difficulty calling indels in this sample, with more than 100,000+ errors in each caller.
Low-Coverage NovaSeq Samples
To further challenge DeepVariant, we applied the method to data from the new NovaSeq instrument. We used the NA12878-I30 run publicly available from BaseSpace. The NovaSeq instrument uses aggressive binning of base quality values and its 2-color chemistry is a departure from the HiSeq2500 and HiSeqX. We made it harder and downsampled from 35X coverage to 19X coverage.
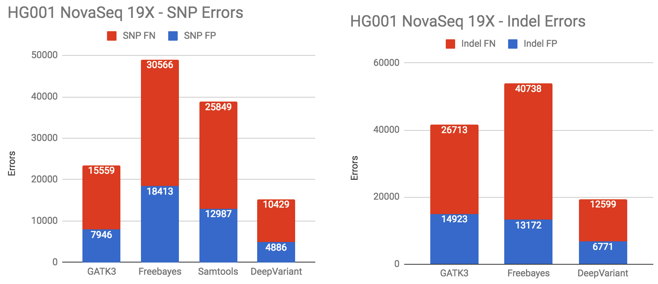
Even in a sample as exotic as low-coverage NovaSeq, DeepVariant outperforms other methods. At this point, DeepVariant has demonstrated superior performance (often by significant margins) across different human genomes, different machines and run qualities, as well as different coverages.
Other Samples
In addition to the benchmarks presented here, we also ran on: 35X NovaSeq data, the high-quality 2016 HiSeqX Garvan Sample, and our HG005 benchmark. In the interest of space, we will skip these charts here. Qualitatively, they are similar to the other graphs shown.
How Computationally Intensive is DeepVariant?
As previously discussed, DeepVariant’s superior accuracy comes at the price of computational intensity. When available, GPU (and someday TPU) machines may ease this burden, but it remains high.
The following charts capture the number of CPU hours to complete the HG001 sample running the pipeline without GPUs (lower numbers are better):
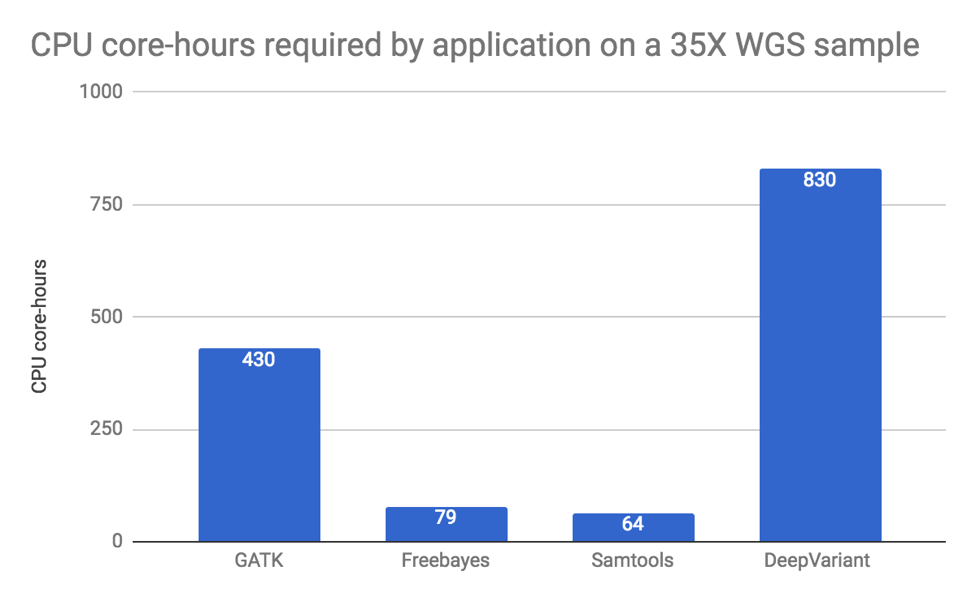
Fortunately, the DNAnexus Platform enables extensive parallelism to cloud resources at a much lower cost. Through the use of many machines, 830 core-hours can be completed in a few hours of wall-clock time. DeepVariant Pilot Program is currently offered to a limited number of interested users, with broader access to the tool in the coming months. Access DeepVariant now on the DNAnexus platform.
In Conclusion
Experts have been refining approaches for the problem of SNP and Indel calling in NGS data for a decade. Through thoughtful application of a general deep learning framework, the authors of DeepVariant have managed to exceed the accuracy of traditional methods in only a few years time.
The true power of DeepVariant lies not in its ability to accurately call variants – the field is mature with solutions to do so. The true power is as a demonstration that with similar thoughtfulness, and some luck, we could rapidly achieve decades of similar progress in fields where the bioinformatics community is just beginning to focus effort.
We look forward to working with the field in this process, and hope to get the chance to collaborate with many of you along the way.


.png)
.png)
.png)