DNAnexus Supports Data Management & Genomic Analysis for a Global Research Consortium
"The DNAnexus global network provides hundreds of researchers at institutions worldwide secure and immediate access and use of ENCODE’s results.”
Overview
In June 2015, DNAnexus announced that Stanford University, the Data Coordination Center (DCC) for the National Institutes of Health (NIH)-funded ENCyclopedia of DNA Elements (ENCODE) Project, a flagship functional genomics consortium funded by the National Human Genome Research Institute (NHGRI) at the NIH, has adopted the company’s cloud genomics platform to support data analysis and sharing for its Phase 3 project. The DNAnexus platform supports the DCC bioinformatics analysis of ENCODE data, making the consortium’s bioinformatics methods available to the broader research community
A challenging objective
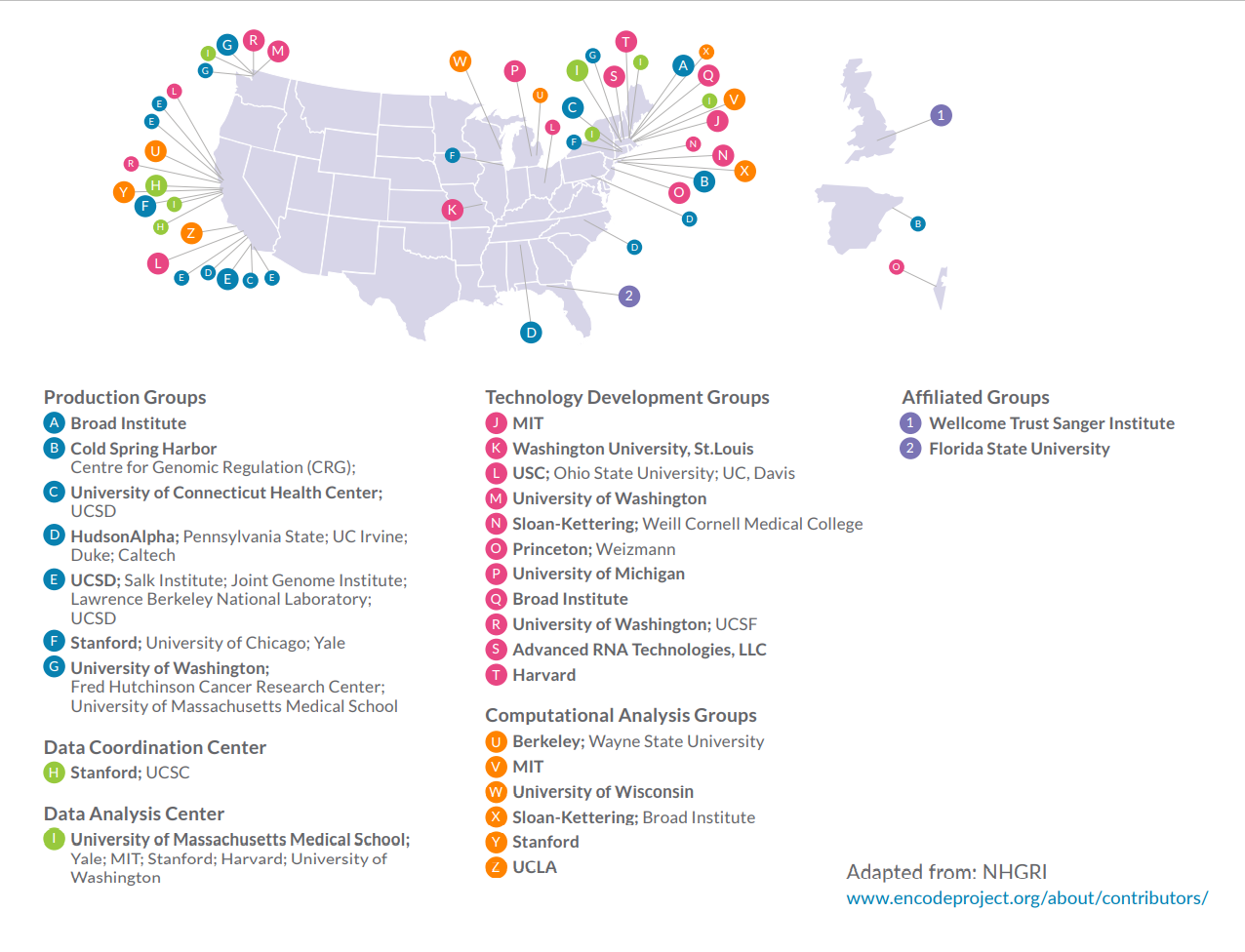
The goal of the ENCODE Project is to comprehensively catalog candidate functional and regulatory elements of the human genome, and provide a foundation for studying the genomic basis of human biology and disease. The ENCODE Consortium includes data production centers and computational biologists at a number of biomedical institutes across North America and Europe.
The ENCODE project is comprised of three phases. Phase 1 (2003- 2007) was a pilot effort for a small portion of the genome. Phase 2 (2007-2012) scaled up to full genome wide analyses. Now in Phase 3, the ENCODE Consortium project is using next-generation technologies and methods to expand the size and scope of catalog content created in earlier phases.
More than scale
Although a scalable solution capable of processing thousands of datasets was a key requirement for the DCC, this was not the only capability needed. The development of version-controlled ENCODE pipelines is a priority in the current phase of the ENCODE project to ensure that data release to the public are consistently processed. Tasked with centralizing the project’s raw and processed sequence-based data using uniform metadata standards and bioinformatics analysis, the DCC will also take advantage of the DNAnexus platform to supply the Consortium with:
- a secure and unified platform already connecting thousands of scientists around the world,
- transparency, reproducibility, and data provenance for consistency amongst ENCODE pipelines and results.
Supporting the encode project network
Stanford University, the ENCODE DCC serves as a data warehouse and processing hub for the ENCODE Project.